Morphemic and Morphological Analysis of the Latvian Language
Ugis Sarkans
Artificial Intelligence laboratory
Institute of Mathematics and Computer science
University of Latvia
Raina bulvaris 29, Riga LV-1459, Latvia
e-mail:
usarkans@ailab.mii.lu.lv
Abstract
In this paper we describe a system of morphemic analysis of Latvian texts and outline further work aimed towards implementing morphological analyser. The basis for our system is regularity of the Latvian language in the sense of word formation. Morphemic analysis is based on morphotactic rules and simple lexicons of morphemes instead of extended traditional lexicons. We describe the process of segmentation, principal constituents of the system and the formal language used for rule description. The system is compared with some other formalisms of morphological analysis and their implementations.
1. Introduction
In this article we discuss a formalism for description of morphemic segmentation rules of Latvian and its implementation in the form of linguist's workbench. In the field of natural language processing it is a usual practice that performance and linguistic "plausibility" are at the opposite ends of scales: if the system is constructed with high performance in mind, it is very often ad hoc with descriptions far from being natural from linguist's viewpoint; and, if the formalism is natural, it is hard to achieve good performance. The Latvian language and its structure from word formation viewpoint seems to be, according to our investigations, suitable for efficient and at the same time natural description of morphemic segmentation rules.
The best approach for morphological analysis for languages that are not highly inflected, like English, is to store all possible word-forms in lexicon, or to use some pattern matching techniques to deal with common affixes. Of course, this applies only if the morphological analyser is the end result and there are no concerns about "the means", i.e., how the morphological descriptions look like. We have tried this method also for Latvian, using the first above-mentioned approach, i.e., storing all possible word-forms. In Latvian there can be about 100 graphically different word-forms of adjectives and, if we consider participles as word-forms of verbs, more than 200 for verbs in the Latvian language. We used a simple method for compressing the lexicon: for every word and all its word-forms the largest common prefix was found, and the remaining parts were stored in a mini-lexicon (c.f. [Koskenniemi 1983]). Thus we had a lexicon of "pseudo-roots" and many mini-lexicons of "pseudo-endings", allowing us to store the whole lexicon in a manageable space without penalty on retrieval time. We are using such morphological analyser in a monolingual Latvian - Latvian electronic dictionary to provide the feature of cross-referencing words from dictionary entries to the main word list.
Still such systems have several drawbacks, the main one being inability to cope with new words that are not present in the lexicon. If we want to link together a morphological analyser with a parser through providing the output of the morphological analyser as the input of the parser, this is an unacceptable situation, especially if the parser is not very robust.
The approach discussed in this paper is more profoundly rooted in the linguistic knowledge; we use the rules of word formation of Latvian.
Modern written Latvian is a comparably new language, and it is quite regular. First, it is regular in the sense of forming inflected forms. For the most part of Latvian words all inflected forms can be obtained from the base form and little supplementary information. Almost the only exception here is certain verbs that require infinitive, past and present stems in order to correctly generate all inflected forms.
Second, our approach is heavily relying on regularity of the Latvian language in the sense of word derivations. Our basic source of linguistic information is [Metuzale-Kangere 1985] that is one of only a few dictionaries of such kind that have been compiled in the world (an indirect evidence of Latvian having exceptionally regular derivational system). Our analyser does not use a lexicon in the traditional sense, i.e., a lexicon containing word stems together with some information necessary for obtaining all inflected forms. We have only lexicons of morphemes, and words are analysed down to the level of single morphemes, not just "stem + inflectional features".
What is very important for our approach of analysing running text without aid of a large lexicon, new words that appear in the language (usually of foreign origin) always are regular from the viewpoint of inflection formation. The group of verbs that require 3 stems (see above) is closed, i.e., new verbs never belong to it.
What is different in our approach compared to the widely known two-level morphology [Koskenniemi 1983]? At the heart of two-level morphology is phonotactics, while we because of our primary concern of morphemic segmentation needed mainly morphotactics. There are several implementations of Koskenniemi's formalism, among them PC-Kimmo [Antworth 1990]. We looked also at PC-Beta [Brodda, Karlsson 1980] that is a general purpose text processing tool. Both these tools require from linguist knowledge of finite state automata; we think that it is easier for linguists to think in terms of morphemes, their adjacency and so on, not in terms of states and automata head movements. Therefore our language for describing morphotactic rules was designed as easy to understand and use as possible without sacrificing generality.
2. Morphemic Analysis
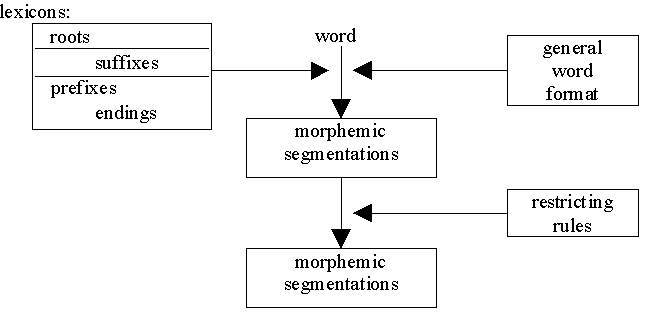
The general schema of our approach to morphemic analysis of Latvian words:
The lexicons of roots, suffixes, prefixes and endings have been taken from [Metuzale-Kangere 1985] and made computer-readable. The general word format of Latvian words (excluding rare compound words consisting of more than two roots) is
<prefix>* <root> <suffix>* [<ending>]
for single-rooted words and
<prefix>* <root> <suffix>* [<ending>] [<prefix>] <root> <suffix>* [<ending>]
for compound words (the possibility of zero or more occurrences of element A is denoted by A*, and optional elements are included in square brackets).
During the first phase of analysis our algorithm produces all possible morphemic segmentations of the word with the structure according to one of the rules and morphemes belonging to the appropriate lexicon.
During the second, more interesting analysis phase new segmentations are not generated; instead, all segmentations obtained during the first phase are validated against a set of morphotactic rules that filter out some of the solutions.
There are rules of general nature, as well as rules dealing with some specific prefixes/ roots/ suffixes/ endings included in the rule set that is used during the second phase. A significant part of rules are included in order to restrict segmentation of compound words (with 2 roots; compound words with more than 2 roots are not analysed by our algorithm). There are about 700 rules at the moment.
The rule language was designed to be both easy to learn and concise. Rules are ordered, and the ordering is important; segmentations are matched against rules always in that fixed order, and processing of one segmentation is interrupted after the first successful match. There are two kinds of rules possible, positive and negative ones. If a hypothetical segmentation matches a positive rule, it is accepted as a correct one. If a segmentation matches a negative rule, it is rejected.
An example of a rule:
$- R[!# cir; bur; kal; ei] | S[!t] S[v]
$- indicates that this is a negative rule. Roots are denoted by R, suffixes by S, prefixes by P and endings by E. This rule indicates that suffix "v" cannot be preceded by other root than "cir", "bur", "kal" or "ei" or suffix "t". ! stands for a kind of negation; if there would be no ! signs in this rule, it would state that suffix "v" cannot be preceded by root "cir", "bur", "kal" or "ei", nor by suffix "t". # indicates list of values, and | is disjunction.
Another example:
$- R[mē] S[!# sl; šan] | E[ ] | P[ ] | R[ ] | .
This rule states the only suffixes that can follow root "mē" are "sl" and "š
an"; no endings, prefixes or other roots can follow it, and it can not be at the end of word.P[3] matches all prefixes with length equal to 3, and S[>2] matches all suffixes with length greater than 2. S[MAX] matches only the longest suffix possible in the respective place.
A problem with such rules is that the rule-set quickly grows and becomes hard to manage, even with extensive commentaries. The task of compiling the rule-set is time-consuming and requires work of highly qualified linguists with deep understanding of diachronic and synchronic aspects of morphotactics.
At the initial stage the work is productive, i.e., there are numerous cases of wrong morphemic segmentations discarded with introduction of every new rule. Later the progress in this sense stalls, there are more and more specific rules needed, even for single words. In principle, after adding each successive rule the rule-set should be tested on all previous examples as well, because interaction between rules is so complicated that it is virtually impossible for the rule set developer to imagine all possible consequences a single rule can cause.
At present we have achieved about 90% accuracy on "real" texts (newspaper and magazine articles). By accuracy we understand the ratio of words that were correctly segmented and the correct segmentation was the only segmentation obtained.
The main practical positive side of our approach is the ability to recognise new words as they appear in modern everyday language. New prefixes, suffixes and endings appear in the language very rarely, if they do at all. The only thing that appears often are roots, and our system can automatically raise hypothesis about new, unseen roots and with approval of the human linguist add them to the list of known roots. The other serious advantage over other methods is that the set of rules developed in the course of work can give valuable insights into morphotactics of the Latvian language because of the easily readable form of rules.
3. Phonemic Variations
Our system is heavily oriented towards morphotactics, and at this stage it is weak in the respect of phonotactics. Our first try at solving the problem of phonemic variations was storing several variations of the same morpheme in the corresponding lexicon. The
analysis of, for example, word "vēža" (singular genitive of "a lobster") proceeded like this: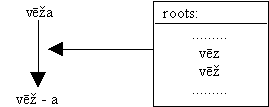
This approach was not satisfactory, both from the viewpoint of linguistic "preciseness" of the underlying formalism and from practical considerations. The next (present) implementation could be shown schematically this way:
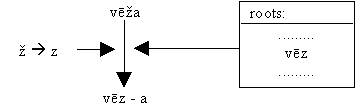
Here phonemic variations are not regarded as separate morphemes, testing the possibility of a variation is built into the program.
We think that for Latvian the best approach is to introduce one more lexicon (besides lexicons of prefixes, roots, suffixes and endings) - the lexicon of phonemic variations. Then this very important aspect of language would not be hidden as in the current implementation:
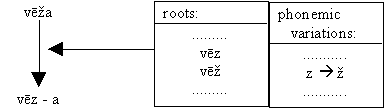
We intend to regard phonemic variations in rules just like other "normal" morphemes. Then it will be necessary to change the rule of the general structure of Latvian words:
.... <root> [<phonemic variation>] <suffix>* ......
4. Morphological Analysis
At present our system performs only morphemic segmentation of Latvian words, it gives no information on possible morphological attributes. We intend to add morphological analysis rules in the form, e.g.,
<noun in genitive> =
= <noun in nominative> - <ending> [ + <phonemic variation> ] + <genitive ending>
Together with morphotactic rules we already have such rule system will be adequate for accurate morphological analysis.
Another direction we are investigating is, how to add higher level, i.e., syntax rules and how they can aid morphological analysis. Here again two kinds of rules are applicable:
Such rules should considerably reduce the number of cases where morphemic segmentation/ morphological analysis is ambiguous, i.e., returns several possible solutions.
In order to decrease the number of rules (both morphotactic and morphological) we intend to add to our system a mechanism for dealing with very irregular words that at present need very specialised rules. It seems to be more natural to include "anomalous" words in some kind of sublexicon and treat them differently from "normal" words.
5. Using Some Ideas of Statistical Language Learning
Statistical language learning is a comparably new and promising field (see [Charniak 1993] for an overview), and there are some approaches we are investigating regarding morphemic and morphological analysis as well.
One of the possible applications of statistical language learning methods can be used for easing the rule development process. Statistics about adjacency of various morphemes can be collected from pre-segmented texts (segmentation performed by hand or by some other method). These statistics can serve for automatic preparation of the first version of the rule set, or for morphemic segmentation entirely based on statistics (i.e., without any rules).
The second idea could be used for reducing segmentation ambiguity caused by the fact that there is no information a priori attached to morphemes on possible word classes where morphemes can be used. Let us explain this idea on an example.
"zut-is" in Latvian means "an eel", and "zus-t" means "to get lost". Both roots "zut" and "zus" are contained in the root lexicon. Suppose the systems has to segment word "zuða". "zuð" is a phonemic variation of both "zut" and "zus", therefore an ambiguity arises. One solution would be to add some ad hoc rule dealing with these words. The other solution for such situations comes from statistical language learning. While analysing texts the system can remember which roots have been seen as constituents of which word classes. If there is a word "zut-im", (singular dative of "an eel"), it is obvious that "zut" here is a root of a noun. If there is a word "zus-t", "zus" is obviously a root of a verb. Now, if "zuða" appears in a place where only a noun is appropriate, most probably "zuð" here is a phonemic variation of "zut" rather than "zus".
6. Conclusion
The Latvian language with its high level of inflections on one hand and regularity on the other hand seems to be a very appropriate language for rule-based morphemic and morphological analysis, as well as for testing various machine learning ideas. It remains to see whether the approach reported here can be used for other languages as well.
Acknowledgements
The work described in this article has been carried out in the framework of a joint research project together with Baiba Kangere from Stockholm University who has been providing most of the linguistic insights; it was financed by Stockholm University. Several researchers of the Artificial Intelligence laboratory, lead by Andrejs Spektors, took part in both theoretical work and practical implementation, especially Baiba Kruze-Krauze, Sandris Imbovics, Inguna Greitane.
References
Evan L.Antworth. PC-KIMMO: A Two-level Processor for Morphological Analysis. Summer Institute of Linguistics, Dallas, Texas, 1990.
Benny Brodda, Fred Karlsson. An Experiment with Automatic Morphological Analysis of Finnish. Institute of Linguistics, University of Stockholm, 1980.
Eugene Charniak. Statistical Language Learning. The MIT Press, 1993.
Kimmo Koskenniemi. Two-level Morphology: A General Computational Model for Word-Form Recognition and Production. Academic dissertation, Helsinki, 1983.
Baiba Metuzale-Kangere. A Derivational Dictionary of Latvian. Helmut Buske Verlag, Hamburg, 1985.